How Shopify Dynamically Routes Storefront Traffic
This post originally appeared on the Shopify Engineering blog on April 9, 2021.
In 2019 we set out to rewrite the Shopify storefront implementation. Our goal was to make it faster. We talked about the strategies we used to achieve that goal in a previous post about optimizing server-side rendering and implementing efficient caching. To build on that post, I’ll go into detail on how the Storefront Renderer team tweaked our load balancers to shift traffic between the legacy storefront and the new storefront.
First, let's take a look at the technologies we used. For our load balancer, we’re running nginx with OpenResty. We previously discussed how scriptable load balancers are our secret weapon for surviving spikes of high traffic. We built our storefront verification system with Lua modules and used that system to ensure our new storefront achieved parity with our legacy storefront. The system to permanently shift traffic to the new storefront, once parity was achieved, was also built with Lua. Our chatbot, spy, is our front end for interacting with the load balancers via our control plane.
At the beginning of the project, we predicted the need to constantly update which requests were supported by the new storefront as we continued to migrate features. We decided to build a rule system that allows us to add new routing rules easily.
Starting out, we kept the rules in a Lua file in our nginx repository, and kept the enabled/disabled status in our control plane. This allowed us to quickly disable a rule without having to wait for a deploy if something went wrong. It proved successful, and at this point in the project, enabling and disabling rules was a breeze. However, our workflow for changing the rules was cumbersome, and we wanted this process to be even faster. We decided to store the whole rule as a JSON payload in our control plane. We used spy to create, update, and delete rules in addition to the previous functionality of enabling and disabling the rules. We only needed to deploy nginx to add new functionality.
The Power of Dynamic Rules
Fast continuous integration (CI) time and deployments are great ways to increase the velocity of getting changes into production. However, for time-critical use cases like ours removing the CI time and deployment altogether is even better. Moving the rule system into the control plane and using spy to manipulate the rules removed the entire CI and deployment process. We still require a “code review” on enabled spy commands or before enabling a new command, but that’s a trivial amount of time compared to the full deploy process used prior.
Before diving into the different options available for configuration, let’s look at what it’s like to create a rule with spy. Below are three images showing creating a rule, inspecting it, and then deleting it. The rule was never enabled, as it was an example, but that process requires getting approval from another member of the team. We are affecting a large share of real traffic on the Shopify platform when running the command spy storefront_renderer
enable example-rule, so the rules to good code reviews still apply.



Configuring New Rules
Now let’s review the different options available when creating new rules.
| Option Name | Description | Default | Example |
| rule_name | The identifier for the rule. | products-json | |
| filters | A comma-separated list of filters. | is_product_list_json_read | |
| shop_ids | A comma-separated list of shop ids to which the rule applies. | all |
The rule_name is the identifier we use. It can be any string, but it’s usually descriptive of the type of request it matches.
The shop_ids option lets us choose to have a rule target all shops or target a specific shop for testing. For example, test shops allow us to test changes without affecting real production data. This is useful to test rendering live requests with the new storefront because verification requests happen in the background and don’t directly affect client requests.
Next, the filters option determines which requests would match that rule. This allows us to partition the traffic into smaller subsets and target individual controller actions from our legacy Ruby on Rails implementation. A change to the filters list does require us to go through the full deployment process. They are kept in a Lua file, and the filters option is a comma-separated list of function names to apply to the request in a functional style. If all filters return true, then the rule will match that request.
Above is an example of a filter, is_product_list_path, that lets us target HTTP GET requests to the storefront products JSON API implemented in Lua.
|
Option Name
|
Description
|
Default
|
Example
|
|
render_rate
|
The rate at which we render allowed requests.
|
0
|
1
|
|
verify_rate
|
The rate at which we verify requests.
|
0
|
0
|
|
reverse_verify_rate
|
The rate at which requests are reverse-verified when rendering from the new storefront.
|
0
|
0.001
|
Both render_rate and verify_rate allow us to target a percentage of traffic that matches a rule. This is useful for doing gradual rollouts of rendering a new endpoint or verifying a small sample of production traffic.
The reverse_verify_rate is the rate used when a request is already being rendered with the new storefront. It lets us first render the request with the new storefront and then sends the request to the legacy implementation asynchronously for verification. We call this scenario a reverse-verification, as it’s the opposite or reverse of the original flow where the request was rendered by the legacy storefront then sent to the new storefront for verification. We call the opposite flow forward-verification. We use forward-verification to find issues as we implement new endpoints and reverse-verifications to help detect and track down regressions.
|
Option Name |
Description |
Default |
Example |
|
self_verify_rate |
The rate at which we verify requests in the nearest region. |
0 |
0.001 |
Now is a good time to introduce self-verification and the associated self_verify_rate. One limitation of the legacy storefront implementation was due to how our architecture for a Shopify pod meant that only one region had access to the MySQL writer at any given time. This meant that all requests had to go to the active region of a pod. With the new storefront, we decoupled the storefront rendering service from the database writer and now serve storefront requests from any region where a MySQL replica is present.
However, as we started decoupling dependencies on the active region, we found ourselves wanting to verify requests not only against the legacy storefront but also against the active and passive regions with the new storefront. This led us to add the self_verify_rate that allows us to sample requests bound for the active region to be verified against the storefront deployment in the local region.
We have found the routing rules flexible, and it made it easy to add new features or prototypes that are usually quite difficult to roll out. You might be familiar with how we generate load for testing the system's limits. However, these load tests will often fall victim to our load shedder if the system gets overwhelmed. In this case, we drop any request coming from our load generator to avoid negatively affecting a real client experience. Before BFCM 2020 we wondered how the application behaved if the connections to our dependencies, primarily Redis, went down. We wanted to be as resilient as possible to those types of failures. This isn’t quite the same as testing with a load generation tool because these tests could affect real traffic. The team decided to stand up a whole new storefront deployment, and instead of routing any traffic to it, we used the verifier mechanism to send duplicate requests to it. We then disconnected the new deployment from Redis and turned our load generator on max. Now we had data about how the application performed under partial outages and were able to dig into and improve resiliency of the system before BFCM. These are just some of the ways we leveraged our flexible routing system to quickly and transparently change the underlying storefront implementation.
Implementation
I’d like to walk you through the main entry point for the storefront Lua module to show more of the technical implementation. First, here is a diagram showing where each nginx directive is executed during the request processing.
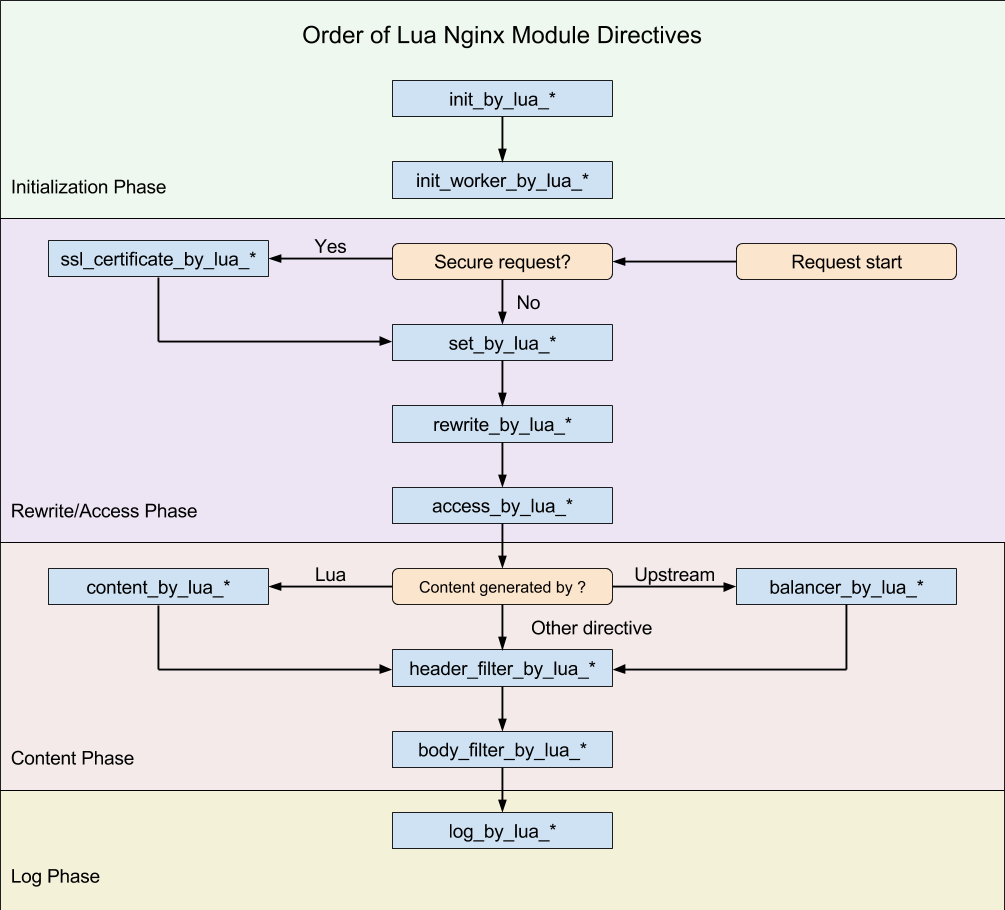
During the rewrite phase, before the request is proxied upstream to the rendering service, we check the routing rules to determine which storefront implementation the request should be routed to. After the check during the header filter phase, we check if the request should be forward-verified (if the request went to the legacy storefront) or reverse-verified (if it went to the new storefront). Finally, if we’re verifying the request (regardless of forward or reverse) in the log phase, we queue a copy of the original request to be made to the opposite upstream after the request cycle has completed.
In the above code snippet, the renderer module referenced in the rewrite phase and the header filter phase and the verifier module reference in the header filter phase and log phase, use the same function find_matching_rule from the storefront rules module below to get the matching rule from the control plane. The routing_method parameter is passed in to determine whether we’re looking for a rule to match for rendering or for verifying the current request.
Lastly, the verifier module uses nginx timers to send the verification request out of band of the original request so we don’t leave the client waiting for both upstreams. The send_verification_request_in_background function shown below is responsible for queuing the verification request to be sent. To duplicate the request and verify it, we need to keep track of the original request arguments and the response state from either the legacy storefront (in the case of a forward verification request) or the new storefront (in the case of a reverse verification request). This will then pass them as arguments to the timer since we won’t have access to this information in the context of the timer.
The Future of Routing Rules
At this point, we're starting to simplify this system because the new storefront implementation is serving almost all storefront traffic. We’ll no longer need to verify or render traffic with the legacy storefront implementation once the migration is complete, so we'll be undoing the work we’ve done and going back to the hardcoded rules approach of the early days of the project. Although that doesn’t mean the routing rules are going away completely, the flexibility provided by the routing rules allowed us to build the verification system and stand up a separate deployment for load testing. These features weren’t possible before with the legacy storefront implementation. While we won’t be changing the routing between storefront implementations, the rule system will evolve to support new features.